CPU Cache 结构
现代多核 CPU 的缓存(Cache)通常分为三级:
- L1 Cache:每个 CPU 核心独有,分为指令缓存和数据缓存。速度最快,容量最小(通常为几十 KB)。
- L2 Cache:每个 CPU 核心独有,不区分指令和数据。速度和容量介于 L1 和 L3 之间(通常为几百 KB 到几 MB)。
- L3 Cache:所有 CPU 核心共享。速度最慢,容量最大(通常为几 MB 到几十 MB)。
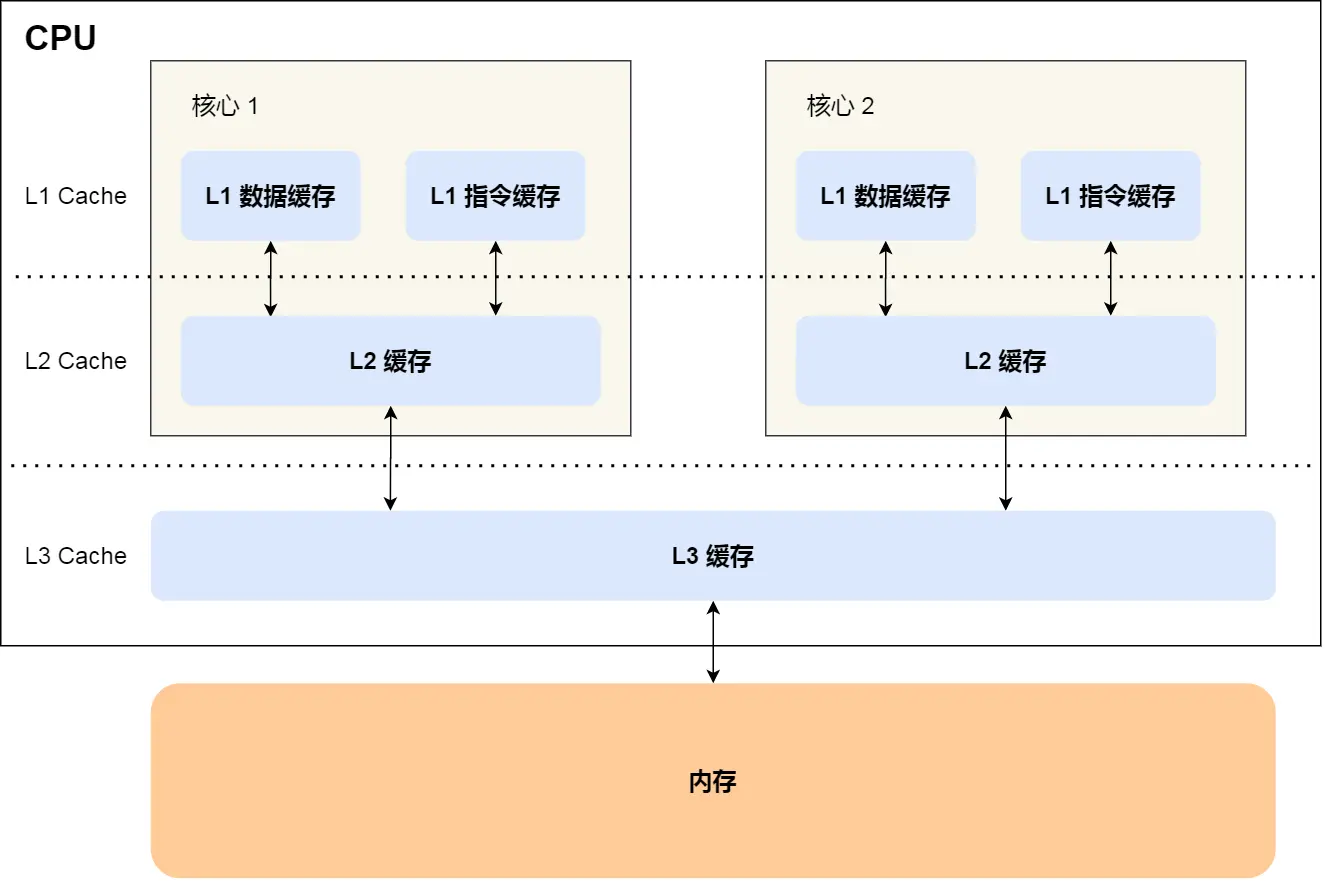
CPU 访问数据的顺序是:L1 -> L2 -> L3 -> 内存。离 CPU 越近的缓存,速度越快,成本越高,容量也越小。
CPU 缓存一致性
由于多核 CPU 存在各自的私有缓存(L1, L2),以及共享的内存,必须有一种机制来保证所有核心看到的内存数据是一致的。这就是缓存一致性(Cache Coherence)问题。
写策略
当 CPU 修改数据时,会先写入 Cache。如何将修改同步回内存,主要有两种策略:
写直达 (Write-Through):每次数据写入 Cache 的同时,也必须立即写入内存。
- 优点:实现简单,能时刻保持内存与 Cache 的一致。
- 缺点:性能受限于内存的写入速度,效率较低。
写回 (Write-Back):数据写入只更新 Cache,同时将该 Cache Line 标记为“脏”(Dirty)。只有当这个“脏”的 Cache Line 需要被替换出去时,才会将其内容写回内存。
- 优点:写入性能高,减少了对内存总线的访问。
- 缺点:实现复杂,存在数据不一致的延时。
现代 CPU 大多采用写回策略以追求高性能。
MESI 协议
为了解决写回策略带来的数据不一致问题,CPU 采用了一系列缓存一致性协议,其中最著名的是 MESI 协议。它通过总线嗅探(Bus Snooping)机制,让每个核心都能监听到其他核心的读写操作,并根据这些操作来维护自己 Cache Line 的状态。
MESI 是四种状态的缩写:
- M (Modified, 已修改):当前 Cache Line 是“脏”的,即内容已被本地核心修改,与内存不一致,且其他核心没有这份数据的缓存。
- E (Exclusive, 独占):当前 Cache Line 是“干净”的,内容与内存一致,且只有本地核心缓存了这份数据。
- S (Shared, 共享):当前 Cache Line 是“干净”的,内容与内存一致,但有多个核心都缓存了这份数据。
- I (Invalid, 已失效):当前 Cache Line 中的数据是无效的,不能使用。
通过这四种状态的流转,MESI 协议确保了任意时刻对于同一内存地址的数据,要么只有一个核心拥有可写的副本(M/E 状态),要么所有核心都拥有只读的副本(S 状态),从而保证了数据的一致性。
利用 CPU Cache 优化代码
理解 CPU Cache 的工作原理,可以帮助我们写出性能更高的代码。核心思想是利用程序的局部性原理:
- 时间局部性:如果一个数据被访问,那么它在不久的将来很可能被再次访问。
- 空间局部性:如果一个数据被访问,那么它邻近的数据也很可能在不久的将来被访问。
1. 利用数据缓存:按内存布局顺序访问
CPU 从内存加载数据到 Cache 时,不是单个加载,而是以 Cache Line(通常为 64 字节)为单位批量加载的。因此,顺序访问连续的内存数据可以最大化 Cache 的命中率。
示例: 遍历二维数组
// 假设有一个 1000x100 的二维数组
let arr = new Array(1000).fill(0).map(() => new Array(100).fill(0));
// 方式一:先行后列(推荐)
// 访问顺序与内存布局一致,空间局部性好
console.time('row_first');
for (let i = 0; i < 1000; i++) {
for (let j = 0; j < 100; j++) {
arr[i][j] = 0;
}
}
console.timeEnd('row_first');
// 方式二:先列后行(不推荐)
// 访问顺序是跳跃式的,每次访问都可能导致 Cache Miss
console.time('col_first');
for (let j = 0; j < 100; j++) {
for (let i = 0; i < 1000; i++) {
arr[i][j] = 0;
}
}
console.timeEnd('col_first');
// 运行结果(示例):
// row_first: 0.3 ms
// col_first: 1.5 ms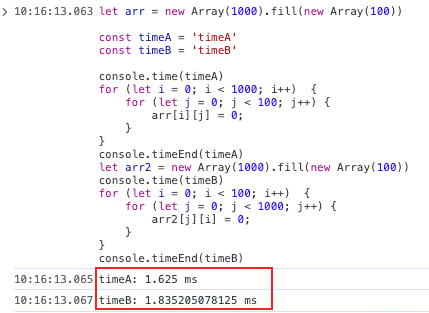
2. 利用指令缓存:减少分支预测失败
CPU 在执行代码时,也会将指令加载到指令缓存中。对于 if-else 或 switch 等条件分支语句,现代 CPU 引入了分支预测器(Branch Predictor)。它会猜测那条分支最有可能被执行,并提前加载和执行该分支的指令。
如果分支预测成功,程序就能无缝执行;如果预测失败,CPU 就必须丢弃已执行的指令,重新加载正确的分支,这个过程会带来显著的性能开销。
优化建议:尽量让代码的分支模式有规律可循。
示例: 对一个数组的数据进行判断,排序后再处理通常比无序处理要快,因为分支预测的成功率会大大提高。

结论
- 数据缓存优化:尽量按照数据在内存中的物理布局顺序进行访问,以提高空间局部性。
- 指令缓存优化:尽量编写有规律的、可预测的条件分支,以提高分支预测的成功率。
贡献者
 jiechen
jiechen